Full-Stack Infrastructure Optimization for High-Performance and QoS-Stable LLM/RAG Serving
Research Axis 1: Infrastructure- and Memory-Centric Optimization for Scalable LLM and RAG Serving
With the rapid proliferation of large language models (LLMs), Retrieval-Augmented Generation (RAG) has emerged as a key technique for improving accuracy and factual reliability. By combining externally retrieved knowledge with generative models, RAG enables domain-aware responses with minimal additional fine-tuning.
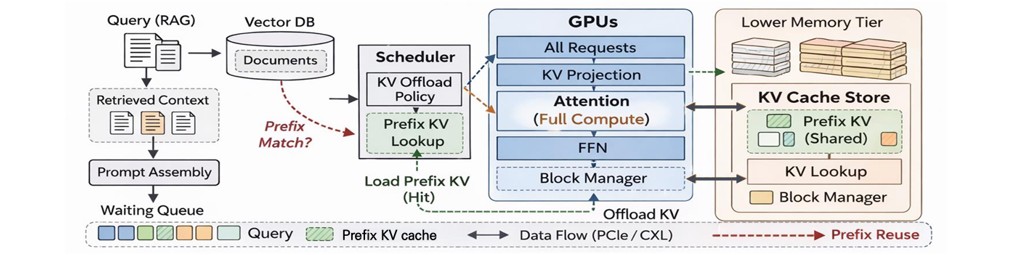
However, RAG-based LLM serving introduces significant system-level challenges. The tight coupling between retrieval and generation stages leads to complex data movement patterns, substantial GPU resource consumption, and high memory bandwidth demands. In particular, the KV (Key-Value) cache generated during inference occupies a large fraction of GPU memory, limiting concurrency and introducing overhead when memory tiering across CPU or storage is required.
This research axis focuses on system-level optimizations in HPC and cloud environments to address these bottlenecks. We explore: Efficient heterogeneous resource utilization across GPUs and FPGAs, Data movement minimization leveraging high-bandwidth memory (HBM) and high-speed interconnects, Hardware-friendly kernel and parallelization strategies, Efficient KV cache management with coordinated scheduling in distributed systems.
Our goal is to design high-performance and cost-efficient LLM and RAG serving infrastructures that scale across large distributed environments.
Research Axis 2: QoS-Aware Adaptive Scheduling for Latency-Stable LLM Serving
Modern generative AI services must handle a massive influx of requests with highly diverse prompt lengths and output characteristics. Efficiently serving such heterogeneous workloads requires more than throughput-oriented optimization; it demands fine-grained control over latency variability and quality-of-service (QoS).
While NVIDIA’s vLLM improves GPU utilization through continuous batching and paged attention, head-of-line blocking remains a major bottleneck. Long-generation requests within the same batch can delay shorter ones, especially during the decoding phase. As output length variance increases, batch reconfiguration overhead grows and KV cache occupancy becomes imbalanced, leading to instability in key service metrics such as TTFT (Time-To-First-Token) and TBT (Time-Between-Tokens).
Under this research axis, we investigate adaptive optimization mechanisms that jointly consider: Output length prediction and token generation patterns, KV cache occupancy dynamics, GPU resource states and memory pressure, Batch reconfiguration and decoding-phase scheduling.
Rather than optimizing throughput alone, our objective is to develop a next-generation LLM serving framework that simultaneously guarantees latency stability, QoS fairness, and cost efficiency in large-scale deployment environments.
Distributed Deep Learning System in HPC and Cloud
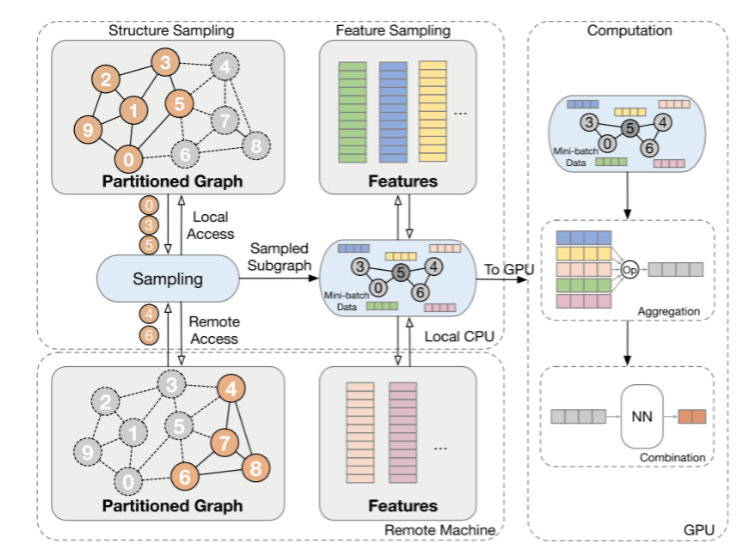
Image Source: : L. Huang et al., "Practical Near-Data-Processing Architecture for Large-Scale Distributed Graph Neural Network," IEEE Access, vol. 10, pp. 46796-46807, 2022.
Recently, deep learning has been playing a crucial role not only in image and language processing but also in social network analysis and recommendation systems. In particular, Graph Neural Network (GNN) models have been gaining attention in these fields. GNN is a deep learning model specialized in interpreting and learning complex graph structures that involve nodes, edges, and their interactions. Due to these characteristics, GNN demonstrates its value in various data represented as graphs, such as user relationship analysis in social networks, predicting properties and reactions of molecular structures, and building personalized recommendation systems. Moreover, GNN effectively combines with distributed deep learning techniques to handle large-scale datasets and complex model structures, maximizing the model's performance and scalability. Distributed learning is implemented through two main methods: model parallelism and data parallelism. A high-performance cluster computing environment is essential for distributed learning. High-performance hardware like GPUs, CPUs, memory, networks, and storage have become the de facto standard for reducing deep learning training time. Based on this technological background, our research lab conducts software optimization research to minimize training time by economically utilizing available hardware resources for various deep learning training and inference tasks, including vision, language, and graph models.
High Performance Vector Database for Vector Similarity Search
Modern AI applications such as RAG, recommendation systems, image/video search, and information retrieval increasingly rely on high-performance vector similarity search. However, existing vector databases often struggle to deliver consistently low latency and high throughput under billion-scale vector datasets or streaming scenarios. To address this issue, our research lab research is designing vector database architecture to handle large-scale vector datasets and production-level workloads including real-time traffic and updates. Our aim is to solve various problems and challenges that arise in storage-based approximate nearest neighbor (ANN) search, large-scale index partitioning with XPU and memory extension, and integrated ANN search into stream processing. Specifically, in storage-based ANN search, we design vector index cache that considers index access patterns and an I/O-friendly index layout to minimize disk I/O at runtime. Additionally, we conduct efficient ANN index partitioning with memory expansion using XPU and remote memory pooling systems. Finally, we are trying to integrate ANN search with stream processing engines, including Apache Spark and Kafka Streams. Overall, our goal is to achieve high performance vector similarity search by optimizing these underlying vector database architectures, thereby accelerating real-world AI and big data analytics workloads.
High-Performance LSM-tree based Key-Value Store
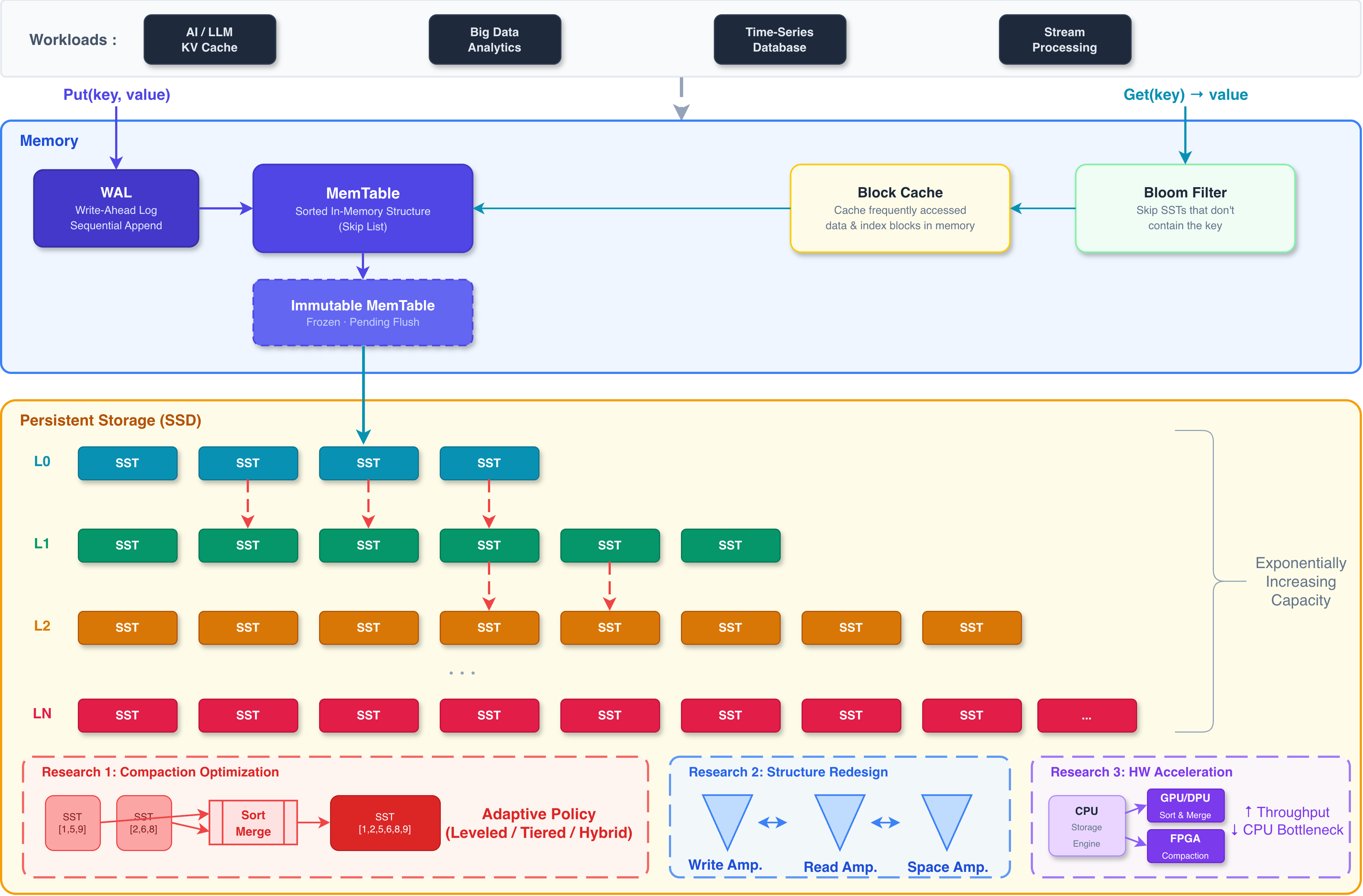
LSM (Log-Structured Merge-tree) based key-value stores deliver outstanding performance for write-intensive workloads and are widely adopted as core storage engines in modern data infrastructure. However, in real-world production environments, several performance bottlenecks persist, including write amplification caused by compaction, multi-level lookup overhead on the read path, and space amplification under large-scale datasets. Our research lab analyzes and addresses these fundamental performance limitations of LSM-tree based key-value stores from a storage systems perspective. Specifically, we investigate methods to optimize compaction policies according to workload characteristics, reducing write amplification while preserving read performance. We also explore redesigning the level structure and data placement of the LSM-tree to effectively control the trade-offs among read, write, and space amplification. Furthermore, we conduct research on offloading computation-intensive operations such as compaction to hardware accelerators including GPUs and FPGAs, thereby improving the throughput of the storage engine. These optimized LSM-tree based key-value stores are applicable to a wide range of AI and big data workloads, including KV cache management for LLM inference. Ultimately, our goal is to build a high-performance storage system that achieves both high throughput and low latency in large-scale data environments.
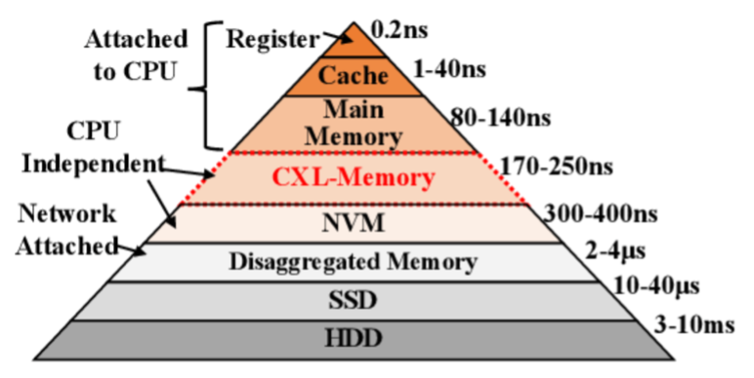
Memory and Storage Architecture for Deep Learning Workloads
Compute Express Link™ (CXL™) is an industry-supported cache coherence interconnect for processors, memory expansion, and accelerators. CXL technology maintains coherence between CPU memory space and memory of connected devices, enabling resource sharing for high performance, reduced software stack complexity, and overall system cost reduction. As accelerators such as GPUs are increasingly used to complement CPUs for emerging applications like artificial intelligence and machine learning, CXL is designed as an industry-standard interface for high-speed communication and has become an industry standard. With CXL, the existing memory hierarchy is becoming deeper, making research on system software applied to operating systems and distributed computing environments increasingly important. Additionally, CXL has been recognized as a highly effective technology for artificial intelligence workloads (such as recommendation models) by providing an expanded, large memory space beyond the limited GPU and CPU memory of the host. In our research lab, we conduct studies to enhance the efficiency of deep learning models for large-scale data-based Graph Neural Network (GNN) based recommendation systems in a disaggregated computing environment like CXL. This involves research on memory, storage, and I/O optimization for improved learning performance and cost-effective computing infrastructure.
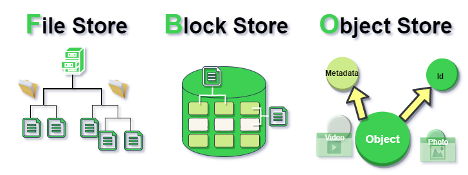
Object Store for AI and Big Data Analytics Acceleration
Image Source: : https://rajkumaraug20.medium.com/file-storage-vs-block-storage-vs-object-storage-2519031a2646
Object storage is a technology for storing and managing data in a format called objects. Modern organizations generate and analyze large amounts of unstructured data such as photos, videos, emails, web pages, sensor data, and audio files. Cloud object storage systems distribute this data across multiple physical devices but allow users to efficiently access content from a single virtual storage repository. Metadata plays a crucial role in object storage technology. In object storage, objects are kept within a bucket and not as files within folders. Instead, object storage combines data chunks that make up a file, adds all user-created metadata to that file, and assigns a user-defined identifier. This creates a flat structure called a bucket instead of hierarchical or layered storage. As a result, objects in a bucket can be retrieved and analyzed based on functions and attributes, regardless of file type or hierarchy. Object storage, not constrained by types, is an ideal storage solution for data lakes that need to accommodate various types of data. Additionally, object storage is suitable for cloud-native applications, large-scale analytics, and machine learning, providing cost-effective, high-capacity data storage beyond data lakes. This contrasts with traditional storage systems that have hierarchical abstraction structures based on files and directories, which fail to properly reflect the requirements of modern applications. This difference originates from fundamental storage design principles that depart from designing data storage based on the concept of files, starting from the input-output unit called blocks. Modern storage systems are at a transitional stage from traditional file-based storage to more flexible and modern object storage systems suitable for contemporary use cases. In line with this, our research lab investigates not only block and file storage management technologies but also object storage-based storage technologies, researching and implementing storage designs optimized for artificial intelligence and machine learning.
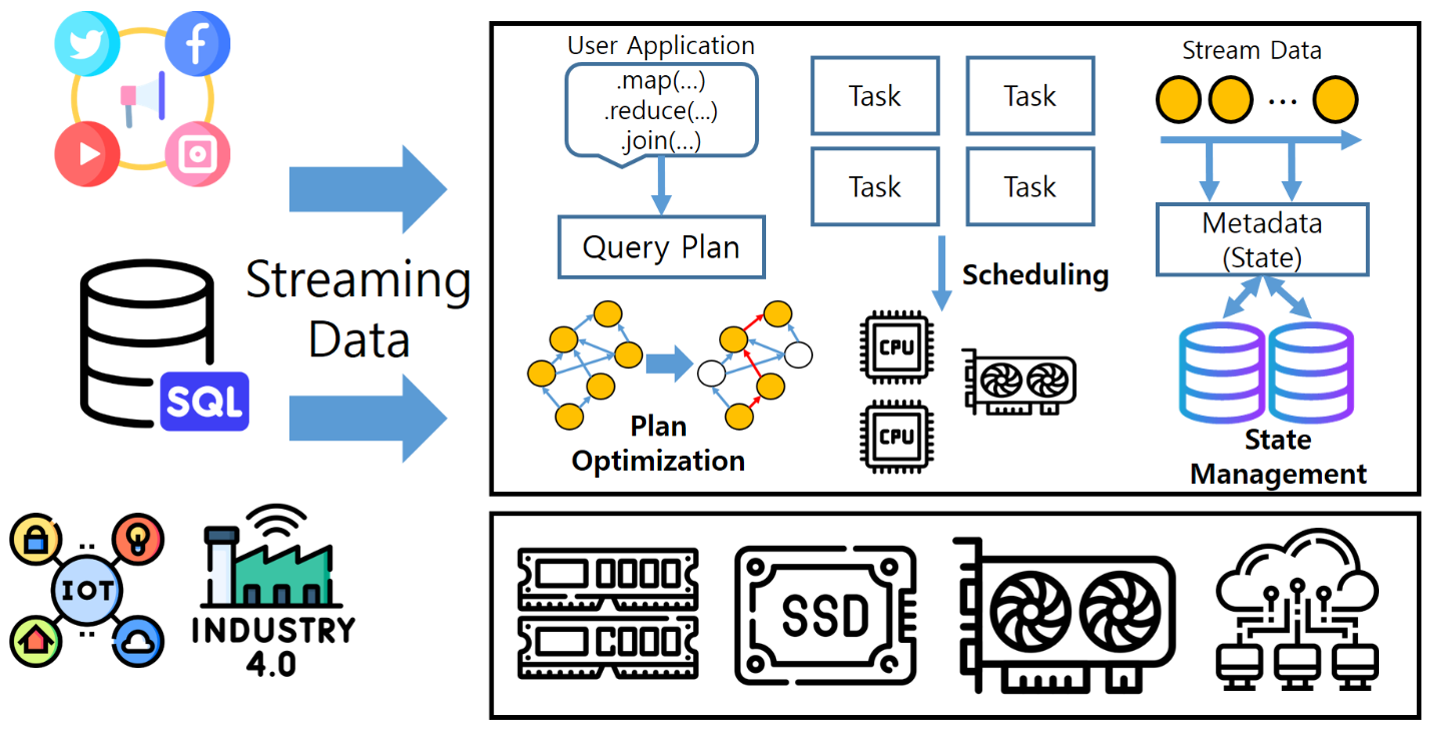
Streaming System Optimization for Query Acceleration
Recently, there has been an increase in services that rapidly analyze large volumes of real-time data incoming from various sources such as social networks, financial transactions, and IoT sensors, and deliver it to users. To achieve this, in-memory-based streaming processing platforms have emerged, which load streaming data into memory for computation. Users execute streaming applications by writing queries combining arbitrary operators (such as map, reduce, join). Subsequently, the streaming system transforms the user's queries into a graph structure and generates the optimal query execution plan. Furthermore, it accelerates data processing by dividing each operator into multiple tasks and assigning them to each CPU core for parallel processing using the map-reduce approach. Meanwhile, heterogeneous computing infrastructures, including cloud and various computing infrastructures, are increasing. However, existing streaming platforms are not optimized for these computing environments, limiting their performance potential. In our research lab, we are conducting studies on optimizing streaming systems considering the characteristics of heterogeneous computing infrastructures (such as CPU, GPU) and accelerating query processing through research on query execution plans, task scheduling, and state management.